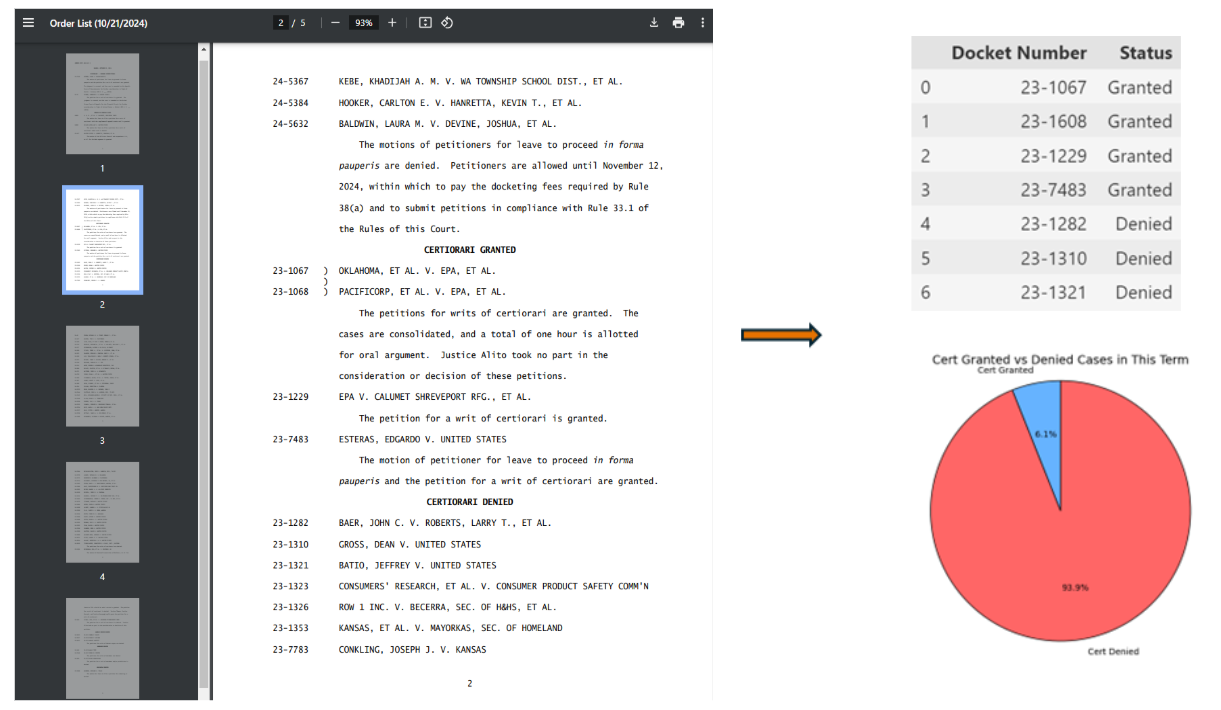
Services
Consultations
Whether you need a second opinion on your latest regression discontinuity design or need help understanding the difference between an independent and dependent variable, the Legal Data Lab is here to help! Our consultations cover everything from basic tutoring on key statistical and data management concepts, to troubleshooting runtime errors in your programming code, to advising clients on the trade-offs between different research designs and modeling strategies. With extensive expertise in data science, the Legal Data Lab is the place to go for statistical and programming advice!
In addition, we provide support for study design and advanced analytic strategies tailored to your research needs. Our expertise encompasses experimental design, psychophysiological measurement, social network analysis, agent-based modeling, and more. We also specialize in applying large language models at scale, utilizing both closed-source platforms (e.g., ChatGPT) and open-source solutions (e.g., Llama). Beyond technical guidance, we frequently offer innovative ideas to help you unlock deeper insights and maximize the value of your dataset.
Data Collection & Cleaning
With years of experience in Stata, R, and Python, we can help optimize the collection and cleaning of research data so that you can focus on running your tests. Scraping websites, joining/merging/slicing/concatenating data frames, or simply pulling data from canned resources like ICPSR or WRDS are daily and well-known activities for us. As librarians, finding the appropriate sources is also a common and familiar task.
Data Storage
Researchers have a few options for storing datasets. Those options are:
- For research that includes a Library-created website, we regularly backup and make copies of the content on the web server, including local copies. If this is an option you would like to pursue, please contact us for more information.
- For researchers who want a place to store their finished dataset, UVA hosts its own instance of Dataverse, a platform for preserving, sharing, citing, and exploring research data. The Law Library has its own "sub-Dataverse" for Law faculty and users can create their own accounts to organize and promote their research. File sizes are limited to 2GB per file and licensing restrictions lean towards broad, public use. For more information see: UVA Dataverse
Visualization
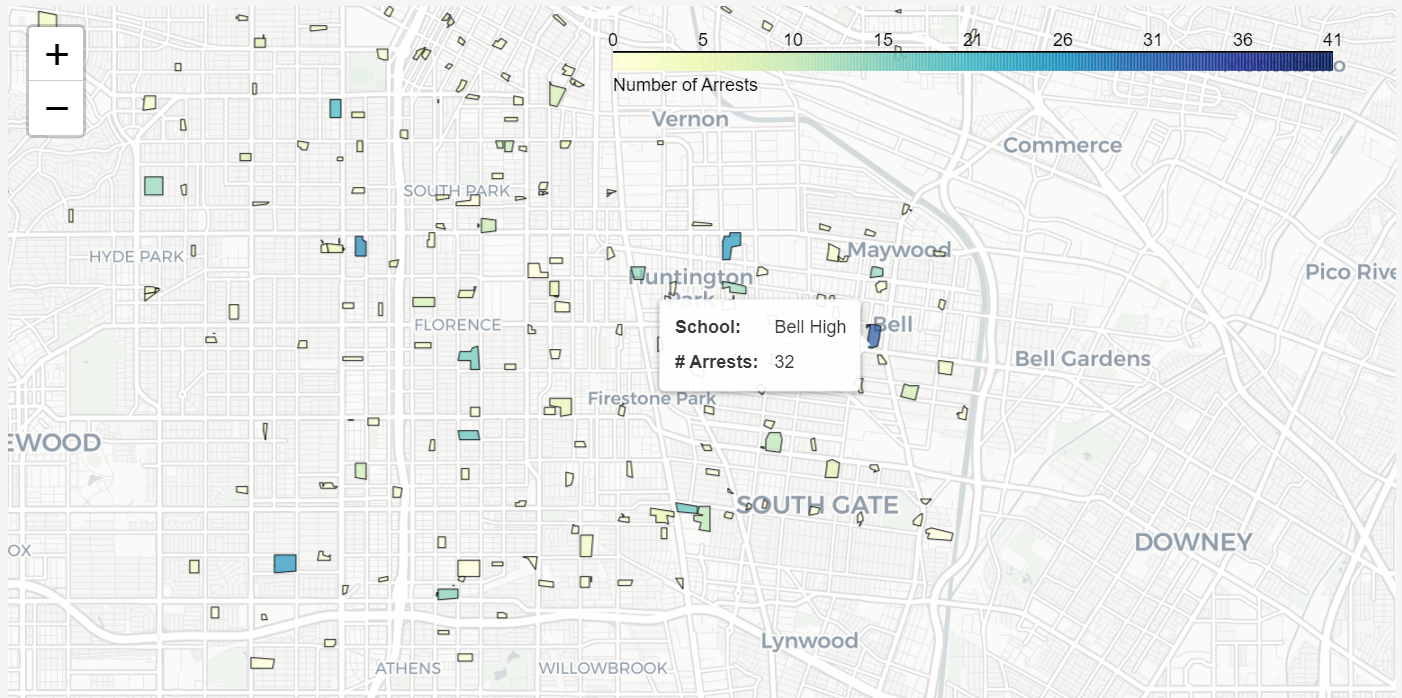
Data visualization can often convey results in a more insightful manner than plain-text stats can. We have experience from hand-coding JavaScript visualizations (with and without D3) to finessing the ever-growing list of visualization packages in R and Python, to outputting basic box plots and histograms. On top of this we occasionally play with ArcGIS when Google Maps and Leaflet don't cut it.
Training
We offer a series of applied trainings on different statistical software and programming packages, as well as specific topics in statistical modeling and inference. We've offered workshops on Natural Language Processing and Survival Analysis in association with UVA StatLab on Main Grounds, and we hope to offer these and other workshops at the Law School in the not too distant future.